[ad_1]
Before you can even think about building an algorithm to read an X-ray or interpret a blood smear, the machine has to know what’s in an image. All of the promise of AI in healthcare – an area that has attracted $ 11.3 billion in private investment in 2021, can’t be realized without carefully labeled data sets that tell machines what exactly they’re looking for.
Creating those labeled data sets is becoming an industry itself, boasting companies well north of unicorn status. Today, Encord, a small startup just out of Y Combinator, is looking to take a piece of the action. Aiming to generate labeled data sets for computer vision projects, Encord launched its own beta version of an AI-assisted labeling program called CordVision. The launch follows pilot programs at Stanford Medicine, Memorial Sloan Kettering and Kings College London. It has also been tested by Kheiron Medical and Viz AI.
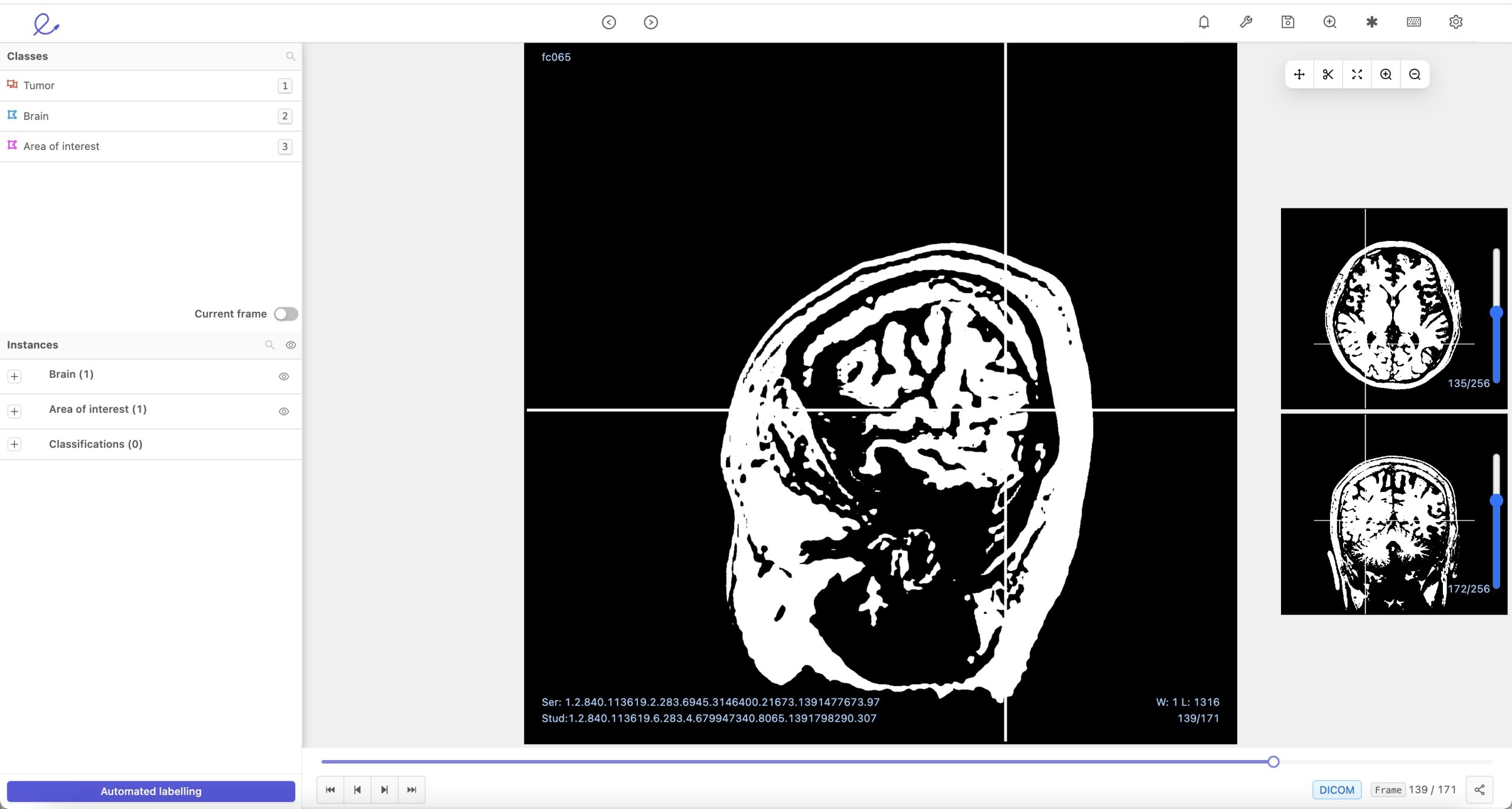
Encord has developed a set of tools that allow radiologists to zoom in on DICOM images, a format universally used to transmit medical images. And instead of having a radiologist sit down and annotate an entire image, the software is designed to ensure that only key portions of the image are labeled.
Encord was founded in 2020 by Eric Landau, who has a background in applied physics, and Ulrik Stig Hansen. Hansen was working on a master’s thesis project at Imperial College London centered around visualizing large medical image data sets. It was Hansen who initially noticed how time-consuming it was to curate labeled data sets.
Those labeled data sets are important because they provide “ground truths” which algorithms can learn from. There are some ways to build AI that do not require labeled data sets, but largely AI (especially in healthcare) has relied on supervised learning, which requires them.
To create a labeled data set, more than one doctor will literally go through the images one by one, drawing polygons around relevant features. Other times, it can be done with open source tools or sensors. But either way, scientific literature suggests this step is a major bottleneck in the healthcare AI world, especially when it comes to radiology, which is one area where AI has been predicted to make major strides, but has largely failed to deliver any major paradigm shifts. .
“I know there’s a lot of skepticism [of AI in the medical world]. We think the progress is really slow, ”Landau told TechCrunch. “We think that transitioning to an approach where you really think about the training data in the first place will help accelerate the progression of these models.”
As the authors of a 2021 paper in Frontiers in Radiology note, it takes human labelers as long as 24 years’ worth of work to label a data set of about 100,000 images. Another 2021 position statement issued by the European Association of Nuclear Medicine (EANM) and the European Association of Cardiovascular Imaging (EACVI) notes that “obtaining labeled data in medical image analysis can be time-consuming and expensive.” But it also points out that new techniques are emerging that can speed things up.
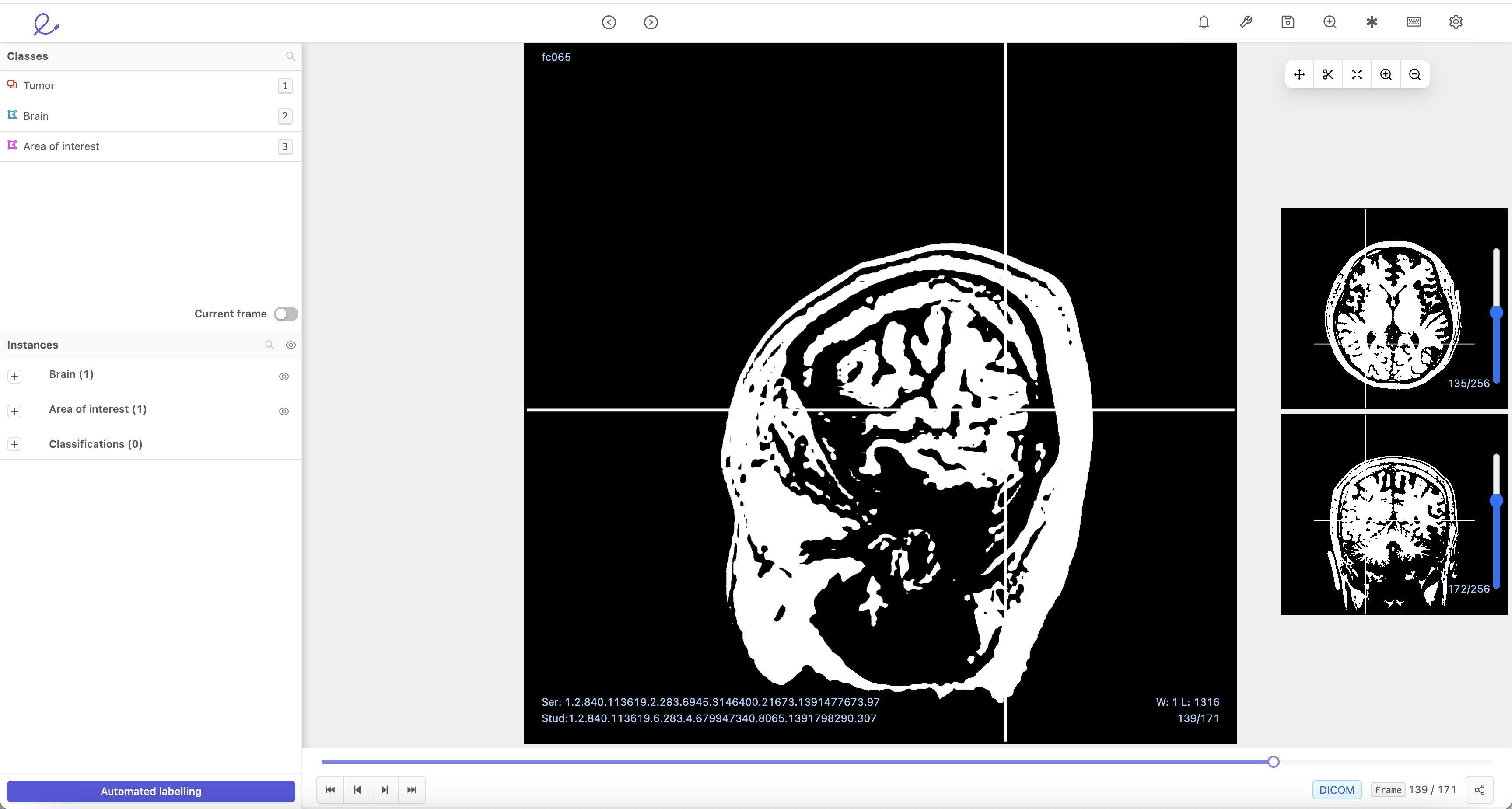
Image Credits: Encord DICOM labeling platform
Ironically, those new techniques are themselves versions of artificial intelligence. That 2021 Frontiers in Radiology paper, for instance, showed that applying an active learning approach, the process could be 87% faster. It would take just 3.2 work-years, as opposed to the 24 years, to go back to the 100,000 images example.
CordVision, basically, is a version of an active learning process called micro-modeling. That technique, broadly, works by having a team label a small, representative sample of the images. Then a specific AI is trained on those images and then applied to the wider pool, which the AI labels. Then human reviewers can check the AI’s work as opposed to doing the labeling from scratch.
Landu breaks it down well in a blog post on his Medium page: Imagine making an algorithm designed to detect The Batman in Batman movies. Your micro-model would be trained on five images depicting the Christian Bale batman. Another might be trained to recognize Ben Affleck’s Batman, and so on. All together, you build the bigger algorithm using each small part, then set it free on the series as a whole.
“That’s something that we found works quite well, because you could get away with doing very, very few annotations and bootstrapping the process,” he said.
Encord has published data to back up Landau’s claims. For instance, one study conducted in conjunction with Kings College London compared CordVision with a labeling program developed by Intel. Five labelers addressed 25,744 endoscopy video frames. The gastroenterologists who used CordVision moved 6.4 times faster.
The method was also effective when applied to a test set of 15,521 COVID-19 X-rays. People reviewed just 5% of the total images, and the final accuracy of an AI labeling model was 93.7%.
That said, Enord is far from the only company that has identified this bottleneck and sought to use AI to smooth out the labeling process. Existing companies in this space are already reporting large valuations. For instance, Scale AI has reached a $ 7.3 billion valuation in 2021 and Snorkel has reached unicorn status.
The company’s biggest competitor, by Landau’s admission, is probably Labelbox. Labelbox boasted about 50 customers when TechCrunch covered them at Series A stage. In January the company closed a $ 110 million Series D putting it within a spitting distance of the $ 1 billion mark.
CordVision is still a very small fish. But it’s caught up in a data labeling tidal wave. Landau says the company is going after places that are still using open-source or internal tools to do their own data labeling.
So far, the company has raised $ 17.1 in seed and Series A funding since graduating from Y Combinator. The company has grown from its two founders to a team of 20 people. Encord, Landau says, isn’t burning through cash. The company isn’t seeking fundraising right now, and believes that the current raises will be enough to get this tool through the commercialization process.
[ad_2]
Source link